

- 囲碁、将棋に用いられるAIがどのように発展していったか
- AIによってテーブルゲームはどういった変遷をしていったのか
- テーブルゲームに用いられるAIはどのような技術が用いられているか
近年、人工知能(AI)は囲碁や将棋といった伝統的なテーブルゲームの世界に革命をもたらしています。これらのゲームは、長らく人間の知性と戦略思考の象徴とされてきましたが、AI技術の進化により、今や人間を凌駕する存在となりつつあります。
本記事では、囲碁や将棋におけるAIの発展とその技術的背景、さらにこれらのAIがどのようにしてゲームの戦略を学び、進化してきたのかを詳しく解説します。先進的なAIシステムがどのようにしてプロ棋士を打ち負かし、ゲームの歴史を塗り替えたのか、その舞台裏を探ります!
囲碁
囲碁AIの歴史
2017年5月27日、囲碁の業界が衝撃を受けた事件が起こります。
アメリカのGoogle DeepMindによって開発された囲碁用人工知能AlphaGoと中国の人類最強の棋士であった柯潔 九段(当時19歳)が三番勝負を行いました。
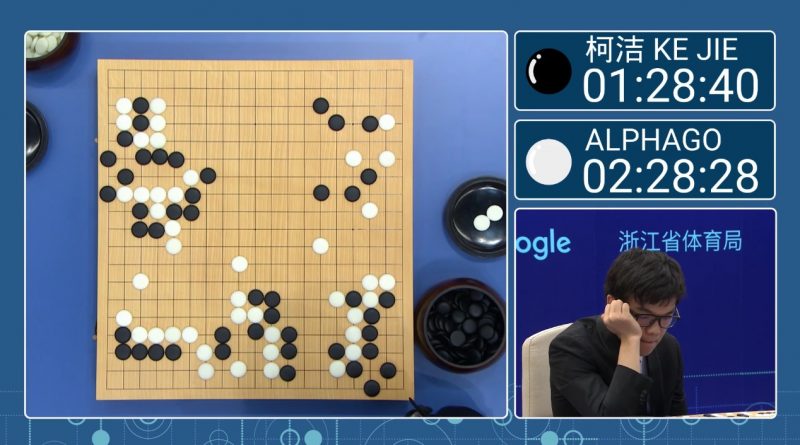
Alphagoと柯潔さんとの対局
3時間20分40秒の対局の末AlphaGoは3対0で勝利しました。この対局は、AIが人間の最高峰の棋士を打ち負かすことができるということを改めて証明し、囲碁界に大きな衝撃を与えました。AlphaGoは、深層学習と強化学習を駆使して、膨大な数の過去の対局データを学習し、自らの戦略を進化させていきました。
囲碁AI実現の壁
囲碁というゲームにおいて、こんなにも早く人工知能(AI)が人を下す未来など、誰も信じてはいませんでした。AI研究者ですらコンピューター開発者も囲碁が人間を超えるには10年はかかると言われていました。
当時、IBMのスーパーコンピュータ「Deep Blue」が、チェスの世界チャンピオンに勝利を収めたり、オセロなどのボードゲームも人間を打ち負かしていたのになぜ…?
DeepBlueが人間を凌駕していた一方、囲碁のプログラムは素人すら相手にならないほど人間に勝つ囲碁のプログラムをつくるのは難しかったんだ
一見チェスなどに比べて単純のように見えますが、囲碁のAIが人間に勝るのが難しかったのは以下の理由があります。
- 盤面の広さと複雑さ: 囲碁は19×19の大きな盤面を持ち、局面のバリエーションが非常に多いため、AIが最適な手を見つけるのが難しいとされていました。これにより、他のゲームに比べて計算量が膨大にであった。
- 局面評価の難しさ: 囲碁では、局面の評価が非常に複雑であり、従来のAIが使用していたヒューリスティック評価関数では十分な精度を得ることが困難でした。
- 探索空間の広大さ: 囲碁のゲーム木は非常に広大で、従来のゲーム木探索アルゴリズム(例えば、ミニマックス法やアルファベータ法)では効率的に探索することが難しかった。
そのためAIが囲碁で人間を打ち負かしたことは囲碁の業界だけでなく、AI研究の分野にも衝撃を与える出来事でありました。
将棋
2023年10月藤井聡太(当時21歳)が史上初の八冠独占を達成して話題となったが、藤井聡太の快進撃の理由のひとつとして将棋AIをうまく取り込んだということもあります。そんな最近では当たり前のように取り入られている将棋AIについて解説していきます!
将棋AIの歴史
2013年5月31日、森内名人と羽生三冠との名人戦七番勝負第5局で森内名人は常識に外れた全く新しい指し方をして、その一手がきっかけで森内名人は羽生三冠に勝利した。

第71期名人戦七番勝負 5局目 左:森内俊之名人 右:羽生善治三冠
将棋の戦法は長年の歴史や研究を通じて確立されているものですが、森内名人はそれに外れた△3七銀の新手に勝つことができました。
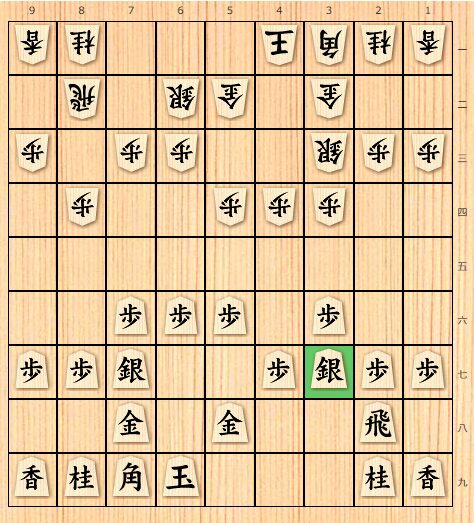
当時の棋譜 森内名人の23手目 3七銀
森内名人はのちに対局中の新手はコンピュータ同士の対戦で出てきた差し方であると明かしました。つまり人工知能が将棋の長い歴史を持つ定跡から外れた新しい一手をAI同士が試行錯誤して生み出したのです。
将棋AIの現在
将棋AIはプロ棋士によって用いられるのが主流となり、藤井聡太王位は「水匠」と呼ばれるAI搭載の将棋ソフトを用いています。
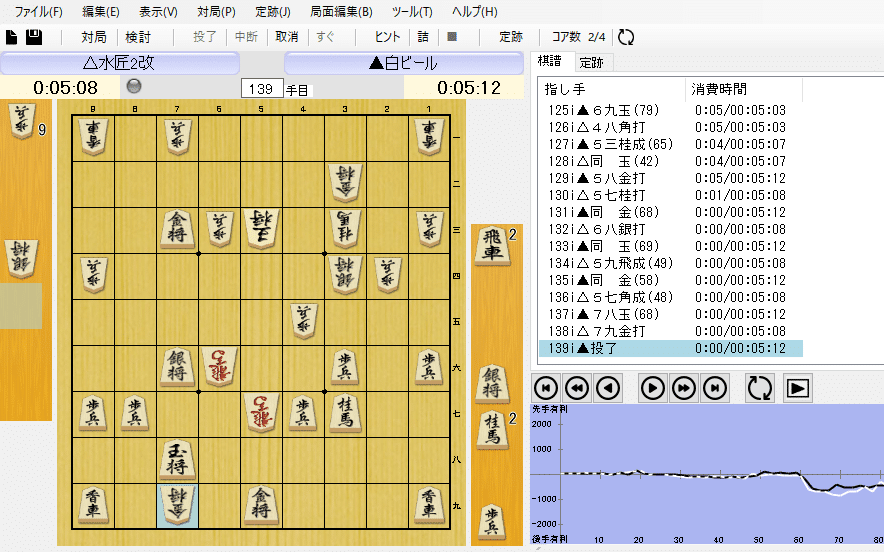
将棋ソフト水匠の画面
AIはプロ棋士に対して以下のように活用されています。
- 対局の分析とトレーニング: AIはプロ棋士が対局を分析するためのツールとして使用されます。AIは局面を評価し、最適な手を提案することで、棋士が自分のプレイを振り返り、改善点を見つけるのを助けます。これにより、棋士は新しい戦略や手法を学ぶことができます。
- 新しい戦略の開発: AIは膨大な数の局面をシミュレーションすることができるため、プロ棋士はAIを使って新しい戦術や定跡を開発することができます。AIが提案する手は、時に人間には思いつかない独創的なものであり、これが新たな戦略の発見につながることがあります。
- 対局相手としての利用: プロ棋士はAIを対局相手として利用することで、実戦に近い環境でのトレーニングが可能です。AIは非常に強力な対戦相手であり、棋士のスキルを向上させるための優れたパートナーとなります。
これらの方法により、AIはプロ棋士のスキル向上や新しい戦略の開発に貢献しています。
テーブルゲームのAIはどのように学習しているのか
では、いったいどのようにして将棋AIや囲碁AIが学習しているのか簡単に解説します。
αβ法
αβ法とはα値(自分)とβ値(相手)それぞれの選択によって分岐するゲーム木を用いてより高い評価値を求める手法です。
ゲーム木を用いてα値ではより自分損失が少なくなるようにしてある損失値を上回る場合にはその選択肢は打ち切る、β値ではより自分の利益が上がるようにしてある利益値が下回る場合はその選択肢を打ち切るようにする。
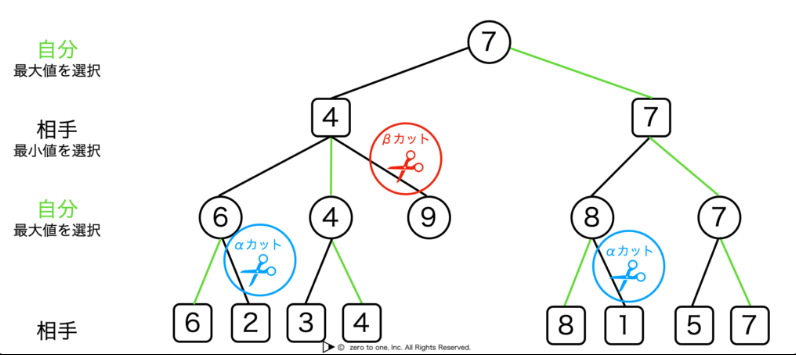
αβ法のゲーム木
(引用 : αβ法とは – 【AI・機械学習用語集】 (zero2one.jp))
つまり、自分の最善手と相手の最悪手を記録していって、結果が良くならない選択を切り捨てるということですね
これらは従来の将棋AIに広く用いられてきました。
モンテカルロ木探索・ディープラーニング
モンテカルロ木法とはテーブルゲームのAIに広く使われている手法です。簡単に言うとゲームの状態を表す樹形図を表す(どこに何をどこまで動かすかなど)そしてランダムなシミュレーションによって最適な打ち手を選択するようにします。
将棋AIではモンテカルロ木法とディープラーニングを組み合わせて学習します。モンテカルロ木探索で行った打ち手を、ディープラーニングを用いた評価関数で評価します。
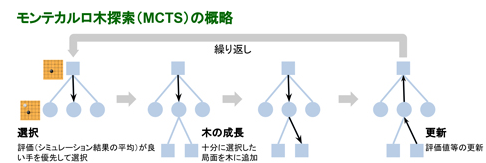
モンテカルロ木法のゲーム木
(引用 : モンテカルロ木探索の改善に関する研究-情報処理学会 (ipsj.or.jp))
難しい言葉で説明してしまったが、つまり勝ちにつながる打ち手をすれば高い報酬を得られると学習させるようにしているんだ
この手法と関連するモンテカルロ法のようにゲームにおいてか選択しうるランダムな事象を膨大な回数を試行させてより良い結果を推定させます。
先ほど紹介したAlphagoは従来の囲碁AIの学習方法に加えてモンテカルロ木法とディープラーニングをうまく組み合わせたことによりより強力なAIとなることに成功しています!
強化学習
AIは対戦を繰り返すことで、試行錯誤しながら徐々に強くなっていきます。これは人間の脳の学習プロセスをモデル化したものです。
- Step1まずプロの棋士からの譜面を学び基礎的な学習をします。
- Step2AI同士が対戦を何度も繰り返して勝敗を記録していきます。
- Step3記録したデータによってポリシーネットワーク(勝ったとき手を高確率で使用するよう学習)とバリューネットワーク(実際の勝敗と予測値の差を小さくするように学習)を更新していきます。
- Step4Step1~Step3を繰り返す
………
AIはこのようにして膨大な可能性の中から最適な手を選択して、AI同士が学習をして人間が長年かけても生まれなかった戦略を生み出しました。将棋AIの成長は今まで人間に与えられたことしかできなかったAIを一つ上の次元に成長させたのです。
ゲームで学習をして成長するAIについて本サイトでは記事をまとめているのでぜひ興味ある方は拝見してみてください!!
AIは我々のようにゲームをできるのか?


